

Hi! I am Aleksey Kladov (aka @matklad). In the past, I've worked at Jet Brains where I've helped to create the IntelliJ Rust plug-in, and now I am a part of the Ferrous Systems team.
I've spent a significant amount of the last year experimenting with various approaches to make the Rust IDE story better. The culmination of my experiments is the rust-analyzer project – an experimental Rust compiler frontend, targeting the IDE/Language Server Protocol use case.
Background
In the 2018 survey, the Rust team identified a number of challenges faced by users of the Rust Language. These challenges include the need for:
- a more improved IDE experience
- a richer ecosystem of tools and support
- support for GUI development
- improved compile times
And was overall summarized as:
Many people commented on the IDE support, pointing out not only instability or inaccuracy in the RLS, but also the need for a much stronger IDE story that covered more areas, like easier debugging.
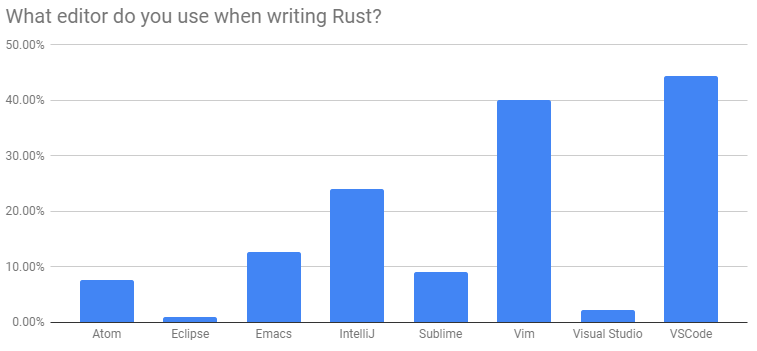
Additionally, the survey showed that most developers used editors such as VSCode, Vim, IntelliJ, and others, which include support for the Language Server Protocol, usable for driving IDE support through external tools.
Why start an experiment instead of hacking on IntelliJ Rust and/or RLS? This is an important question, so I'll answer it in depth. Keep in mind that I was a primary maintainer of IntelliJ Rust for a long time, so my views are biased.
IntelliJ Rust
IntelliJ Rust is in a very good state. There's no doubts that it doesn't cover 100% of the Rust language yet and that the performance could be significantly better, but these are engineering questions. Most major pieces: lossless parsing, macro expansion, on-demand name resolution, and cached type inference are already in place, together with an ever-expanding set of user-visible niceties built on top of this core.
The only fundamental problem with IntelliJ Rust is that it is not written in Rust, and I would really love to have a pure-rust solution for IDEs. Why? The main reason is that Rust is the perfect language for building these sorts of tools, so not having a good self-hosted solution is a shame. The second significant reason is that Rust-based tooling would be much easier to reuse across the Rust ecosystem.
RLS
Why not just hack on the RLS then? I did contribute a number of PRs to RLS, but fundamentally I believe that while undeniably RLS works today and is immensely useful for a huge number of people, its current architecture is not a good foundation for a perfect IDE long-term.
One approach to turn a command-line compiler into an IDE is to run the build of the project with a special flag to make the compiler dump all the information about the program into some kind of JSON database. The IDE then reads this database to answer queries like "go to definition", "find reference", etc.
This is more or less what RLS does today, in part because it is a relatively
low-effort approach which allows to implement a subset of IDE features
relatively quickly. Specifically, this solution works perfectly for certain
IDE-like scenarios, where the code does not change. Think rustdoc, or DXR-like
code browsers, or the recently introduced LSIF.
However, this approach does not work as well for the case where the user actively types in new code.
- This approach assumes that the project can be built, which is often not the case:
- the build system may be custom
- the build script may have a bad day
- you might be editing a file which is not a part of the project
- the new code may contain errors which prevent everything else from working.
- It is inefficient: On every modification, you need to ask the compiler to refresh the database, although chances are you'll inspect only a tiny fraction of the database before the next invalidating modification comes in.
- It has high latency: because build is costly, it is invoked at most once per x seconds, which means you either have to wait to get the results, or get stale results.
- It's not flexible. When implementing assists and refactorings, you need access to the concrete syntax tree (with comments & whitespaces), and you can benefit greatly from accessing internal compiler data structures to learn fine-grained information. A JSON database approach usually don't give you such things.
What are the alternatives? Another approach (which is used by rust-analyzer) is to get rid of the explicit notion of "compilation" request, and instead pursue a full-stack on-demand model. Analyzer maintains a "database" of input facts (source code + information about project structure) and derived facts (syntax trees, name resolution information, types). The client then can change input facts, and query derived facts at the current state of the world.
Computation of derived facts happens transparently (there's no "we schedule compilation every two seconds" step), incrementally (if the last change didn't affect the fact, we reuse it) and on demand (only the minimal amount of facts necessary to answer the query is computed).
The last point is crucial, and is one of the critical problems of the "JSON database" approach. One of the main tricks which makes IDEs responsive for multi-million line projects is that they can show errors only for the currently open file and avoid looking at the large part of the rest of the code.
I think due to the way Rust crates work we might actually be able to pull "show all errors" feature with acceptable performance, but we still need full on-demand for more latency-critical features like completion.
State of rust-analyzer
So, what is the current state of rust-analyzer, what can it do? If you approach it from an IDE user perspective, not much:
- fuzzy-search all symbols in workspace/crates.io dependencies,
- semantic selection (select enclosing expression, statement, item, etc)
- running a single test/main function under cursor
- immediate syntax errors reporting
- simple completion & go to definition for local variables and imports ( from the current workspace only)
- parser based syntax highlighting
- syntax-based intentions (add derive, add impl, flip
,around, introduce variable) - some more minor things
Here's a short video demonstration:
While the first two features are necessary and sufficient for me to feel minimally productive (I do use rust-analyzer as my Rust IDE nowadays), you will be much better served by IntelliJ Rust (whose features are a strict superset) or RLS (which can't do some things like semantic selection and single test running, but which has other niceties, most notably in-line error annotations).
But the infrastructure behind these features is pretty exciting. One of main concerns about implementing a Rust IDE in Rust for me was that IntelliJ platform has all kinds of cool libraries for building IDEs: indexes, caches, parser generators, fancy data structures. Turns out, by leveraging crates.io ecosystem you can have all these nice things in Rust as well! They are not so well-tuned for the IDE use-case as IntelliJ, but they definitely are enough to unblock the progress.
The starting point of an IDE is a error-tolerant parser and lossless syntax
tree. rust-analyzer has both, and the syntax tree is published to crates.io as the
rowan crate. It is heavily inspired by IntelliJ's PSI and by Swift's
libsyntax (which in turn is inspired by Roslyn).
Awesome fst crate by @BurntSushi is used to implement fuzzy symbol search.
One of the most important infrastructure bits, on demand and incremental
computation, is handled by the fresh salsa crate by @nikomatsakis. In some
ways salsa is more powerful than the caching strategies currently employed by
IntelliJ Rust. I've been chatting with current IntelliJ maintainers about
applying salsa-like strategy to name resolution in the plugin :)
And of course the Rust language itself helps tremendously with figuring out the proper concurrency and change management. For IDEs, you want to be able to analyze code in parallel, quickly apply changes from the editor/file system and cancel in-progress work when modification comes in. This is a really complicated problem, but Rust surfaces this complexity, so it becomes much easier to manage.
The two major missing bits are persistence of analysis results to disk and correct management of file-system changes.
2019
At this point, rust-analyzer is an explicitly experimental project, it does not try to be useful for general public. My primary plan for 2019 is to start bringing its ideas to production.
The main thing we should do is to form a long-term vision for the architecture of Rust IDE support. The original RLS RFC 1317 was written a while ago, and we've gained an enormous amount of field experience of what works and what doesn't with both RLS and IntelliJ. We should reflect on this data and adjust our strategy accordingly. Crucially, this should involve folks from IntelliJ, RLS and compiler teams, which are, unfortunately, mostly disjoint.
I personally feel that aiming for a separate IDE-first implementation in the short-mid term might be a good idea. This should allow easier experimentation with various approaches before picking a good one and refactoring rustc itself to use it. It's also interesting that all languages with excellent IDE support I know of used a from-scratch implementation for IDE:
- Java, C# and Dart by having a parallel "IDE" re-implementation in addition to original "batch compiler".
- Kotlin and TypeScript by making the original implementation IDE-first.
It might seem that, for Rust, a separate front-end implementation is an enormous task, but projects like IntelliJ Rust and mrustc show that this is doable.
Rust Research Compiler
An interesting difference between rustc/RLS and rust-analyzer is how much easier
the analyzer is to hack on. It is just a usual Cargo package, which builds on
stable compiler (1.31.0) with cargo build, has unit-tests, etc. Unlike
rustc, there's no complicated bootstrapping process, dynamic libraries
shenanigans or building the LLVM. This is not some deliberate engineering
effort: it's just that rust-analyzer doesn't actually generate machine code, so
it can get rid of a lot of complexity.
This property might be useful to make it easier to experiment with the rust
language for research purposes. It's much easier to add formal verification,
change how borrow-checker works or play with coherence if you don't need to
build rustc.
Sharing Code With rustc
Instead of full re-implementation, we can swap rustc components
bit-by-bit, until it becomes a perfect compiler for IDE-purposes. This is a very
exciting approach, but feasibility depends on technical details.
We probably can share the parser quite easily with some effort (and with large
effort to make the parser both correct and error tolerant). Adding lossless
syntax trees to rustc seems much more complicated though. Sharing macro
expansion and name resolution hence seems quite challenging.
On the other hand, some more high-level bits already exist as libraries (chalk &
polonius), and probably can be reused.
Replacing the rustc Frontend
Yet another approach is to merge two strands of development higher in the stack,
by implementing all front-end bits in rust-analyzer, and delegating code-gen to
the existing back-end. This I believe is the approach which was used by dotty,
which shares a common codegen back-end with scalac.
Interested in Funding this work?
The work on rust-analyzer is currently sponsored by Ferrous Systems GmbH. If you are interested in further sponsoring this work to:
- Reach a stable 1.0 state
- Extend rust-analyzer functionality to cover your internal or open source tooling needs
- Add first class support of rust-analyzer to your IDE
please contact us for more details!





