
In about 4 weeks time from the publish date of this blog post, you'll be able to use the async/await feature in no_std code on stable! In this blog post we go over the work we did to make it happen and what we learned from building a proof of concept executor for the ARM Cortex-M architecture.
TL;DR
- We did work in the compiler (
rustc) to enable the async/await language feature inno_stdcode - While making this possible, we were also able to improve the compilation time and runtime performance of async code for everyone
- These improvements are already available in the latest beta release and will reach the stable channel in 4 weeks
- We were able to build a proof of concept async
no_stdruntime and test out some async applications on a ARM Cortex-M microcontroller - We want the community to take these efforts further, but if you want a production ready solution now you can contact us for a quote!
Good-bye TLS, hello compile-time & runtime perf gains
async/await is implemented as a source code transformation in the compiler. This transform lowers async blocks (async { }) to generators and had previously been employing Thread Local Storage (TLS) to pass a task::Context argument from the executor to the (nested) async blocks that make up a task.
The transform had been using TLS because the generators that async blocks desugar into hadn't provided a way to take arguments. The use of TLS made async/await not work in no_std code where TLS, and threads, are not defined – it is common for embedded no_std applications, even multitasking ones, to not depend on threads.
The first step to remove the TLS dependency was to add support for resume arguments to generators (see #68524, #69302 and #69716). This new language feature made it possible to pass arguments to generators through their resume method. The next step was to change the async/await desugaring to use resume arguments instead of TLS (see #69033).
While working on these implementation PRs, Jonas observed a few spots in rustc's async/await code base that could be simplified and landed 2 PRs that improved the compile times of async code: #68672 and #68606. Each of these PRs separately improved the compile time of one of the async compile-time benchmarks that live in rustc test suite – which are used to detect compile-time regressions – by 60%. Note that these benchmarks are stress tests of the async feature so compile time gains in real world async code will be much more modest.
Not content with just improving compile time, Jonas also improved the machine code generation in two follow up PRs: #69814 and #69837. The first one removed panicking branches that were impossible to reach at runtime from code compiled with the panic=abort codegen option, which is what most embedded no_std code is compiled with. The second PR reduced the (mem::size_of) footprint of the futures returned by async blocks and async functions.
Perf gains for everyone
Thanks to this work, all users of async/await will be observing improved codegen (that is: code runs faster) and compile times in the next (1.44) stable release.
Shortly after the last of these PRs landed, a Rust developer on reddit reported a huge reduction in the machine code produced for a simple I/O-less nested (depth = 2) await invocation (shown below). Before these changes the code produced ~100 x86_64 machine instructions, including panicking branches. With these changes the compiler was able to perform the computation at compile time and the generated machine code was reduced to a single "return answer" instruction.
Source code analyzed:
async fn foo() -> u32 {
3
}
async fn square() -> u32 {
let a = foo().await;
let b = foo().await;
a * b
}
pub fn xx(cx: &mut Context<'_>) -> u32 {
let mut f = square();
let mut f = unsafe { Pin::new_unchecked(&mut f) };
loop {
if let Poll::Read(x) = f.as_mut().poll(cx) {
break x;
}
}
}
Output machine code, after our compiler work:
example::xx:
mov eax, 9
ret
That's the sort of improvement you'll see in code generation, which means your async code will run faster.
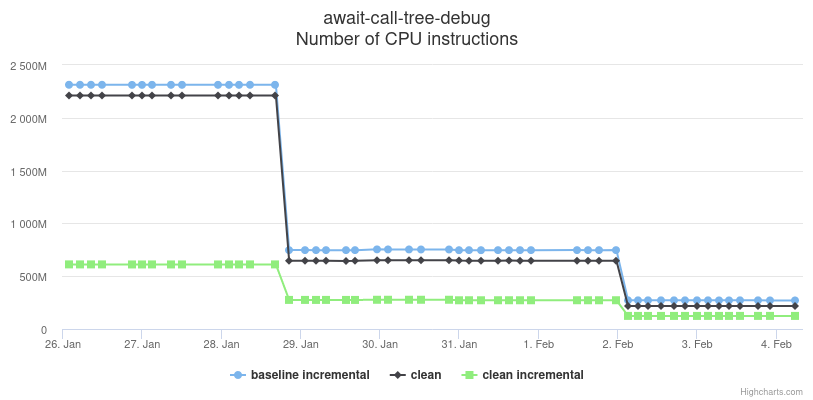
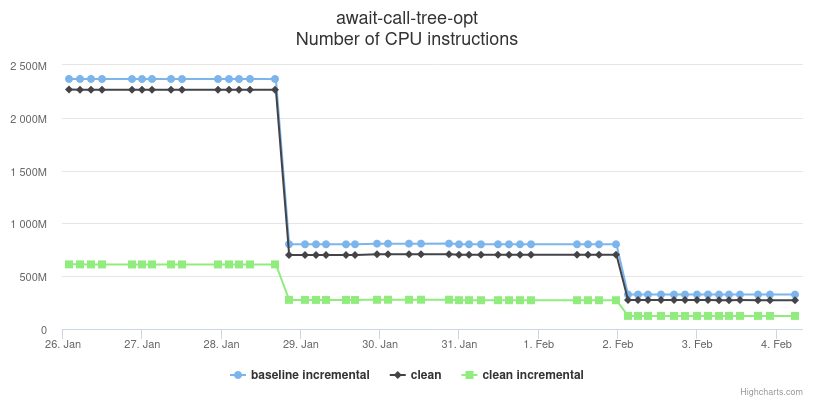
On the compile time front, the graphs below (there's an interactive version of them here but it won't be kept indefinitely) show the improvements in the compile time, measured as number of executed CPU instructions, of the await-call-tree benchmark. The top graph corresponds to a dev build (contains debug info; not optimized); the bottom graph corresponds to a release build (no debug info; optimized). The first ~70% dip seen in the graphs is due to PR #68606; the second additional ~20% dip is due to PR #68672.
no_std async in action
As an internal project we built a proof of concept executor for the ARM Cortex-M architecture and wrote some example applications. Here's what we learned.
Opt-in heap & code reuse
We identified two broad usage categories:
- convenience is preferred over fine grained control over resources like memory and CPU time. Here an
async_std::task::spawn-like API that heap-allocates, short-lived or never-ending, tasks is a great fit.
- you have a fixed number of, likely never-ending, tasks and/or can upper-bound the number of tasks you periodically spawn. Here you can make do without a memory allocator and statically allocate memory for the tasks.
Applications can fall in either category depending on the requirements of the application and the resources available on the device that will be running the application.
It's possible to build an executor that accommodates either usage pattern (our PoC was geared towards the first pattern). Either executor variant will be able to run the same async HAL (Hardware Abstraction Layer) code and async application logic with some differences in how tasks are spawned.
We expect to see many async executors in the future, each one with different runtime properties tailored to the diverse requirements of embedded applications, but thanks to the common interfaces defined in core::future and core::task those executors will be able to run the exact same async code. Meaning that application developers will be able to try out different executors and pick the one that fits their needs the best. Even better, they can start with a convenient executor that heap allocates to speed up the development phase and then switch to a more resource efficient one when they start optimizing for cost / power efficiency.
async sharing
"How to communicate with multiple I2C devices connected to the same I2C bus?" is a question that comes up from time to time in the Matrix chat of the embedded Rust working group. The most common answer thus far has been to use a mixture of (disable all interrupts) critical sections and panicky RefCells to appease the compiler.
async provides a more elegant solution to the problem: async mutexes (pictured below). These mutexes let sensor drivers "lock" the bus for complete I2C transactions. While locked other (async) tasks that try to claim the bus mutex will enter a suspended state and only be resumed (woken up) when the bus mutex is released. These mutexes can be implemented without critical sections or RefCells.
let i2cbus = /* .. */;
// asynchronous mutex
let shared_i2c = Mutex::new(i2cbus);
let i2csensor1 = Sensor1::new(&shared_i2c);
let i2csensor2 = Sensor2::new(&shared_i2c);
let task_a = async {
// ..
let reading = i2csensor1.read().await;
// ..
};
let task_b = async {
// ..
let reading = i2csensor2.read().await;
// ..
};
// omitted: spawn the tasks on the executor
A good fit for time-sensitive code
Plenty of existing std async code is high-level networking code: HTTP, TCP, UDP, etc. where the physical layer (Ethernet, WiFi) is abstracted away (handled) by the OS. We have first-hand experience running full-stack no_std async code in USB devices and IEEE 802.15.4 radios (see tweet below) and we think async is also a great fit for this kind of I/O, despite it having more challenging timing requirements (microsecond response times on CPUs clocked at tens of MHz).
USB <=> IEEE 802.15.4 (radio) bridge in ~25 lines of async #embedded #rustlang
— Jorge Aparicio (@japaric_io) April 23, 2020
also 3 different Rust programs running on 3 different devices that talk to each other, all orchestrated with a few plain `cargo run` invocations
alt video link: https://t.co/cndVgxq1K5 pic.twitter.com/nUq2n2MSum
A bright future
async no_std code will only continue to improve and evolve over time. Here are some of things we are keeping an eye out for.
async trait methods
We are really looking forward to async trait methods (see below). This language feature will enable truly zero cost async interfaces – the existing workarounds for the lack of this feature, like the async_trait macro, result in one heap allocation per trait method call which likely is too expensive for smaller embedded devices.
trait AsyncRead {
type Error;
// this method returns a future
// the returned future may freeze `self` or `buf` or both
async fn read(
&mut self,
buf: &mut [u8],
) -> Result<usize, Self::Error>;
}
stable global_alloc
Global allocators (#[global_alloc]), and therefore the alloc crate, cannot yet be used in no_std applications on stable – the alloc crate can be used in libraries on stable though – because the #[alloc_error_handler] attribute, which is used to declare how the Out Of Memory condition is handled, is still a unstable feature. We hope to see #[alloc_error_handler] stabilized in the near future as this would let executors use the global allocator for their internal heap allocations while still working on stable.
Many possibilities
So far async code's main use cases have been hosted applications, specially web servers, running on OSes like Linux. These applications are usually concerned about throughput and being able to efficiently use the many cores available on a server.
Embedded applications on the other hand usually run on single-core devices and, in addition to optimizing for power / CPU efficiency, may also need to respond to (external) events in a timely fashion. To meet these time constraints embedded applications prioritize each part of their programs differently. Task, or thread, prioritization is a feature commonly found in embedded OSes but that has so far been missing from std executors. We believe we'll be seeing no_std executors with support for task prioritization in the future.
Another potential area of exploration is writing time-sensitive interrupt handlers as async code. These handlers are usually complex state machines and although one can write them today using enums and match statements rewriting them as async tasks would yield linear and easier to read code.
On both fronts, the Real Time for The Masses framework looks like a great starting point for this exploration work as it already implements task prioritization and supports binding tasks to events.
We are proud to have enabled the async feature in no_std and embedded code and we hope that our proof of concept, which is permissively licensed, will serve as a starting point for async HALs and no_std executors. We are looking forward to the many asynchronous abstractions the embedded community comes up with!
Ferrous Systems is a Rust consultancy based in Berlin. Here's how we can help you out:
Help you ship embedded async code today
Want to take advantage of async/await in your embedded project today?
Even though async trait methods have not been implemented and global_alloc is still unstable in no_std code we can still build you an async executor and an async HAL that will compile on stable Rust 1.44+. No need to wait for new language features or stabilization of existing language features, get a head start and leverage async/await today.
Contact us for more details.
Get faster compile times
Not happy with the compile times of your Rust project?
We can profile the compiler on your code base and help you optimize your code base for compile times and/or optimize rustc itself if you are hitting a corner of the compiler that has not yet been optimized.
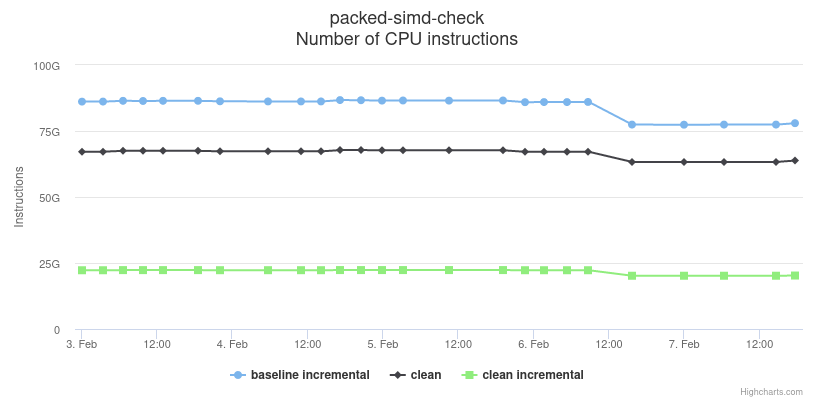
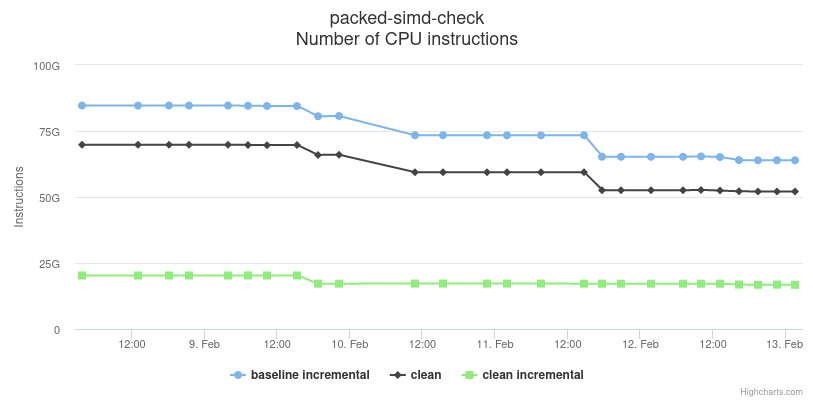
Here two more compile time graphs that show some of our compiler work. These correspond to the packed-simd benchmark, which contains a large number of impl items and is similar in terms of type checking workload as Peripheral Access Crates (libraries used in embedded code to access peripherals) generated by the svd2rust tool. The compile times correspond to a cargo check invocation, which runs the compiler's type checking and linting passes but skips code generation and linking. The top graph (interactive) shows a 5-10% dip that corresponds to PR #68837. The graph on the bottom (interactive) shows a series of improvements product of PRs #68911 (5% dip), #68966 (10% dip) and #69044 (10% dip).
Contact us for a quote.
Train your team
We also offer remote training on basic Rust; advanced topics, like async/await; and applied Rust, like Rust on embedded systems — to receive our updated training program, subscribe to our newsletter.
Oxidize Conf
We are the organizers of Oxidize Conf, a recurring embedded Rust conference. We'll have more updates about the next iteration pretty soon!





